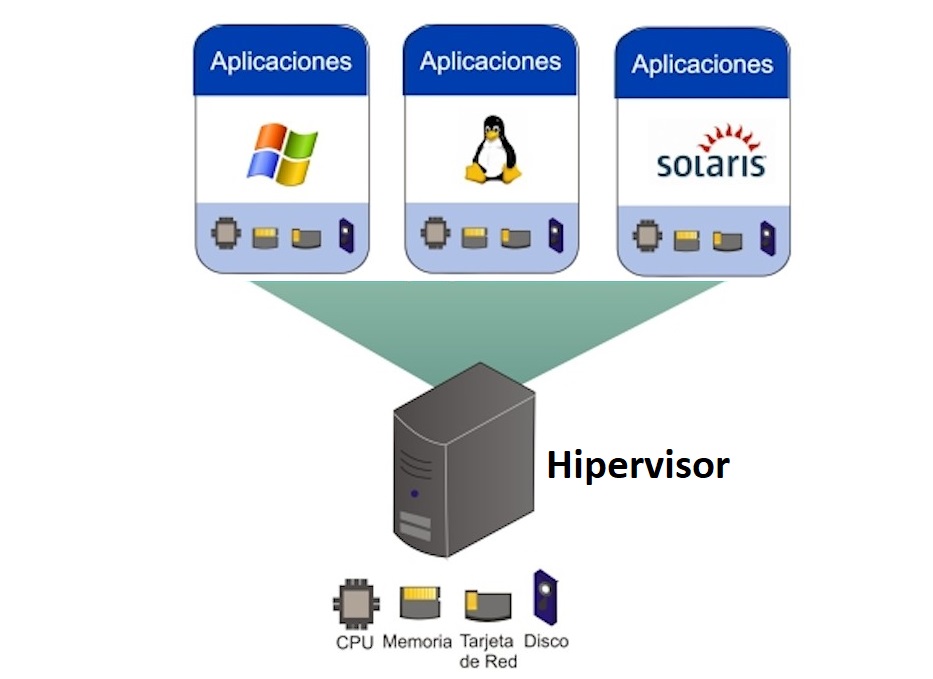
El diagnóstico en entornos virtualizados se ha convertido en una habilidad crítica para administradores, ingenieros de sistemas y especialistas en infraestructura. A diferencia de los sistemas tradicionales, la virtualización introduce una capa adicional de abstracción donde múltiples máquinas virtuales comparten recursos físicos, lo que complica la identificación de fallos. Cuando aparece un problema —de rendimiento, disponibilidad o estabilidad— es fundamental aplicar técnicas de diagnóstico adecuadas para determinar la causa raíz y resolverlo rápidamente antes de que afecte a todo el entorno.
Comprender cómo se comportan los recursos, qué procesos intervienen en la cadena de virtualización y cómo interactúan las máquinas virtuales entre sí es esencial para realizar diagnósticos efectivos. En este artículo se exploran los métodos más utilizados, las herramientas más comunes y las prácticas recomendadas para abordar cualquier incidencia en un entorno virtual moderno.
1. Entendiendo el comportamiento del sistema antes de diagnosticar

El diagnóstico no comienza cuando aparece un error, sino mucho antes. Un profesional debe conocer cómo debería comportarse el sistema en condiciones normales para poder identificar cuando algo no está funcionando correctamente.
Línea base de rendimiento
Establecer una línea base significa recoger datos habituales de carga de CPU, uso de memoria, IOPS de almacenamiento, latencia de red y consumo de recursos por máquina virtual. Estos datos permiten:
- Detectar anomalías con mayor rapidez.
- Diferenciar entre un pico temporal y un problema real.
- Determinar si el host está subdimensionado o sobrecargado.
Cuando no existe una línea base, cualquier intento de diagnóstico se vuelve más complejo, ya que no hay una referencia clara de qué valores se consideran normales.
Conocimiento del entorno
Un administrador debe saber:
- La topología del hipervisor.
- La configuración de las máquinas virtuales.
- Dependencias entre servicios.
- Políticas de almacenamiento y red.
Sin esta información, los diagnósticos se convierten en una serie de pruebas a ciegas.
2. Identificación y clasificación del problema
Antes de buscar la causa raíz es necesario identificar el tipo de problema. En virtualización, los fallos suelen clasificarse en cuatro categorías principales:
Problemas de rendimiento
Incluyen:
- CPU al 100%
- Latencias elevadas en disco
- Contención de memoria
- Red saturada
Estos problemas afectan la velocidad de las aplicaciones y suelen ser los más urgentes.
Problemas de disponibilidad
Ocurren cuando una máquina virtual o servicio deja de estar accesible. Normalmente están asociados a fallos del host, interrupciones en la red o sistemas operativos bloqueados.
Problemas de configuración
Surgen por cambios incorrectos en parámetros de red, hardware virtual, políticas de almacenamiento, drivers o snapshots.
Problemas intermitentes
Los más difíciles de detectar porque no dejan rastros evidentes. Suelen estar relacionados con picos de carga, hardware degradado o procesos en conflicto.
La clasificación inicial permite escoger las herramientas correctas y acotar la búsqueda.
3. Diagnóstico de recursos del hipervisor
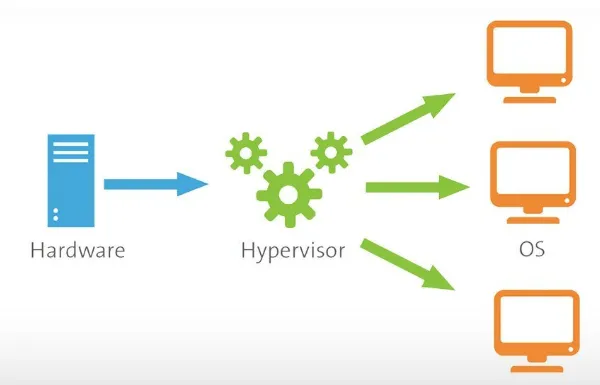
Uno de los pasos más importantes consiste en revisar qué está ocurriendo a nivel del host físico. El hipervisor es la base de todo el entorno, y cualquier sobrecarga en este punto afecta directamente a las máquinas virtuales.
CPU
Una contención de CPU ocurre cuando varias VMs intentan usar más ciclos de los disponibles. Para diagnosticarlo se utilizan métricas como:
- Ready time
- Steal time
- Uso por vCPU
- Overcommitment ratio
Valores elevados indican que el host está saturado o mal configurado.
Memoria
Los problemas de memoria pueden detectarse revisando:
- Uso de RAM real
- Swapping del host
- Ballooning en VMs
- Presencia de técnicas de compresión o deduplicación
Si el hipervisor comienza a intercambiar memoria en disco, el rendimiento general cae drásticamente.
Almacenamiento
El almacenamiento suele ser uno de los recursos más sensibles. Para diagnosticarlo se revisan:
- IOPS disponibles frente a los usados
- Latencia de lectura y escritura
- Saturación del datastore
- Fallos en controladoras o red SAN
Muchas incidencias de lentitud se originan aquí.
Red
Una red virtual mal configurada genera fallos difíciles de detectar. Se analizan:
- Ancho de banda
- Pérdida de paquetes
- Saturación en switches virtuales
- VLANs incorrectas
Los problemas de red pueden parecer fallos de software cuando en realidad son configuraciones inadecuadas.
4. Análisis dentro de la máquina virtual
Una vez descartado el hipervisor, el siguiente paso es entrar en la VM afectada y revisar su sistema operativo. Las máquinas virtuales tienen sus propios procesos, logs y configuraciones, y un fallo interno puede parecer un problema de la infraestructura.
Procesos y servicios
Comprobar:
- Procesos que consumen CPU
- Servicios bloqueados
- Bloqueos de memoria
- Errores de aplicaciones
En muchos casos, el problema es interno y no tiene que ver con el host.
Saturación de discos internos
Aunque el datastore tenga espacio libre, una VM puede quedarse sin espacio en su propio sistema de archivos. Esto genera errores de:
- MySQL
- Apache/Nginx
- Windows Update
- Servicios que requieren espacio para logs
Actualizaciones o drivers faltantes
Una VM con drivers VirtIO, VMware Tools o Guest Additions desactualizados puede tener:
- Mala conectividad
- Lentitud extrema
- Incompatibilidad con funciones del hipervisor
5. Análisis de logs: la clave para el diagnóstico preciso
Los logs son la herramienta más importante para descubrir la causa de cualquier problema. En la virtualización existen tres niveles de logs que deben revisarse.
Logs del hipervisor
Incluyen:
- Errores en discos o datastores
- Fallos de migraciones en caliente
- Interrupciones de energía
- Conflictos en snapshots
- Advertencias de hardware físico
Estos registros permiten detectar problemas globales.
Logs de la máquina virtual
En Linux se revisan:
/var/log/syslog/var/log/messages/var/log/dmesg
En Windows:
- Visor de eventos
- Registros de aplicaciones y sistema
Aquí suelen encontrarse errores de aplicaciones, servicios, drivers o kernel.
Logs del almacenamiento o red
Equipos como switches, routers, NAS o cabinas SAN también generan registros que pueden contener la clave del problema.
6. Uso de herramientas especializadas de diagnóstico
Para analizar entornos virtualizados existen numerosas herramientas diseñadas específicamente para detectar y aislar fallos.
Herramientas nativas del hipervisor
Dependiendo de la plataforma, se pueden utilizar herramientas como:
- vSphere Client / vCenter
- Proxmox VE Monitor
- Hyper-V Manager
- XenCenter
- Cockpit para KVM
Permiten observar métricas en tiempo real, gestionar logs y visualizar alertas.
Herramientas de rendimiento dentro de la VM
En Linux:
top,htopiotop,iostatvmstatnetstat,ss
En Windows:
- Monitor de rendimiento
- Resource Monitor
- Process Explorer
Estas herramientas sirven para analizar comportamientos específicos dentro de la máquina.
Sistemas de monitoreo externos
Plataformas como:
- Prometheus + Grafana
- Zabbix
- Nagios
- PRTG Network Monitor
Ayudan a recopilar datos históricos y correlacionar eventos.
7. Pruebas cruzadas y aislamiento del problema
Una técnica fundamental en diagnóstico es aislar la variable que está provocando el fallo. Esto implica:
- Migrar la VM a otro host
- Probar la red en otro segmento
- Cambiar la controladora del disco virtual
- Asignar más o menos recursos
- Desactivar servicios temporales
Si el problema desaparece tras un cambio, se confirma el origen.